Want more wrestling news, rumors, and results? Be sure to visit PWInsider.com and PWInsiderXtra.com.


In the fast paced world of digital media, the ability to produce high quality assets on a restricted timeline is often the difference between a project's success and its failure. Independent filmmakers and social media influencers frequently face the daunting task of finding original music that fits their specific narrative without infringing on complex copyright laws. Integrating an AI Music Generator into the standard production pipeline offers a scalable solution that bypasses the traditional delays associated with music licensing or custom composition. By utilizing these tools, creators can generate a library of unique assets that are perfectly synchronized with their visual content, allowing for a level of creative control that was previously reserved for large scale studios with massive budgets.
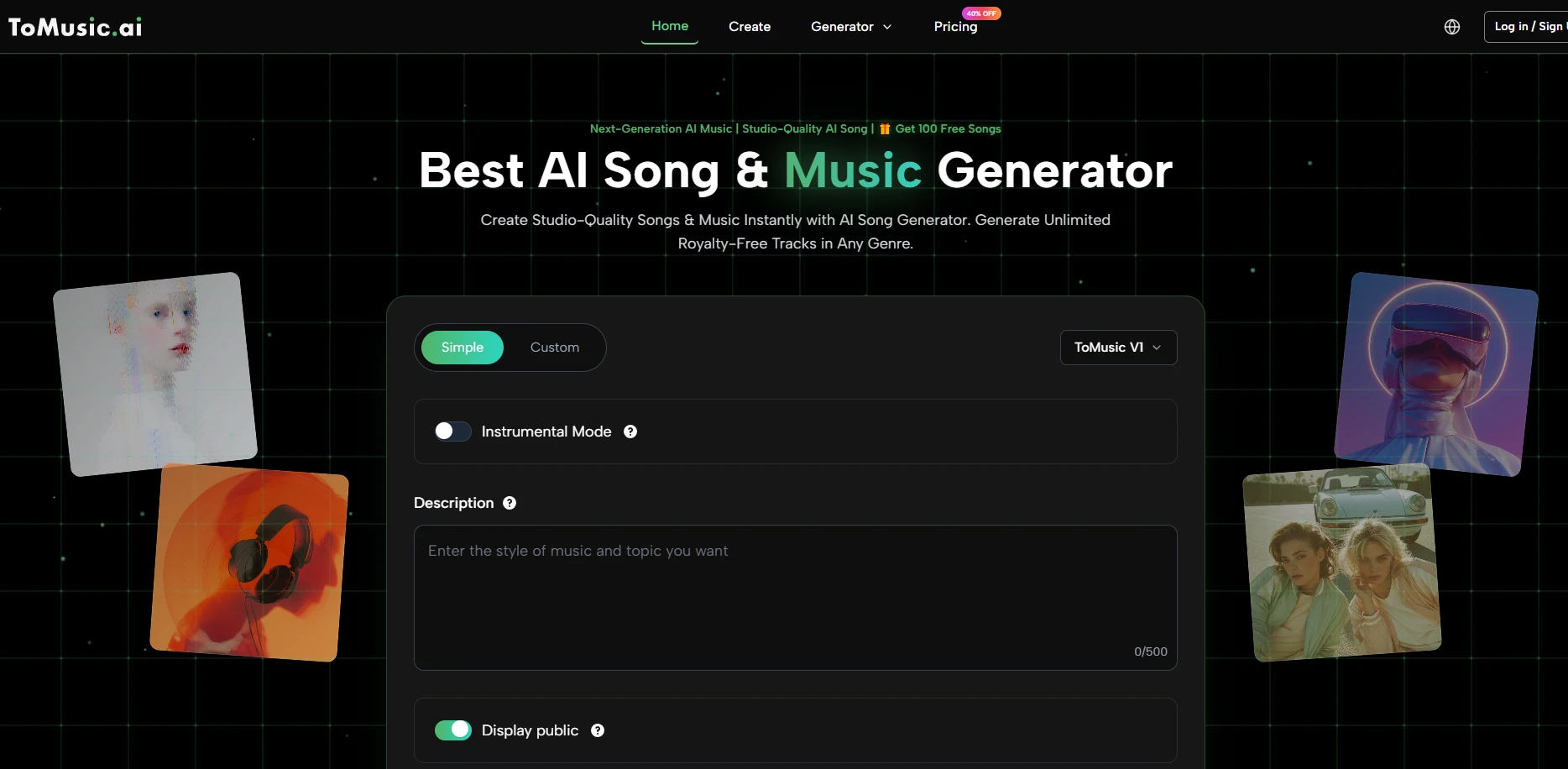
The traditional workflow for finding music involves hours of scouring stock libraries, often resulting in a "close enough" solution that doesn't quite capture the intended atmosphere. When a project requires a specific change in tone during the editing phase, the process starts all over again. Automated synthesis allows for instant prototyping, where a creator can test different musical directions in minutes rather than days. This speed is critical when working under tight deadlines for clients or platform algorithms. In my experience, the ability to generate a placeholder track that eventually becomes the final score significantly reduces the friction between the initial concept and the final delivery.
While many casual users are satisfied with standard compressed formats, professional media production requires a higher standard of audio fidelity. The availability of lossless formats like WAV is essential for ensuring that the music can withstand the rigors of professional mixing and mastering. When audio is compressed into an MP3, certain frequencies are stripped away to reduce file size, which can lead to a "thin" or "brittle" sound when played on high end speakers. By exporting in a lossless format, creators preserve the full dynamic range of the generated performance. This allows the audio to sit perfectly in a mix alongside professional voiceovers and sound effects.
One of the most significant advantages of using generative audio is the clarity of ownership and usage rights. Traditional music licensing is a minefield of "sync rights," "mechanical rights," and regional restrictions that can lead to content being flagged or demonetized. Using a dedicated platform ensures that the assets generated are royalty free, meaning the creator does not have to pay ongoing fees for the use of the music. This is particularly important for those looking to monetize their content on YouTube or social media. However, it is always advisable to verify the specific licensing tier of your subscription to ensure that full commercial rights are granted for your specific use case.
|
Operational Comparison Item |
Entry Level Production |
Professional Studio Tier |
|
Audio File Format Options |
Standard Compressed MP3 |
Lossless 24-Bit WAV Files |
|
Commercial Licensing Scope |
Restricted Personal Use |
Full Global Commercial Rights |
|
Project Storage Capacity |
Temporary Cloud Access |
Permanent Unlimited Storage |
|
Model Version Access |
Legacy Generation V1 |
Advanced Multi Model V1-V4 |
|
Processing Speed Priority |
Standard Shared Queue |
High Priority Private Server |
|
Post Production Support |
Single Mix Output |
Full Multi Track Stem Access |
The process of music supervision often involves a difficult translation of abstract feelings into technical musical terms. A director might ask for something that feels "shimmering" or "heavy," which a composer then has to interpret. The Text to Music interface acts as a bridge in this communication gap, allowing the director to directly input those descriptive terms and hear the immediate sonic interpretation. This level of direct interaction empowers the non-musician to take an active role in the composition process. In my testing, this lead to more cohesive projects where the music felt like an extension of the visual narrative rather than an afterthought.
Define the narrative intent by entering a combination of lyrics and stylistic descriptions into the generation interface.
Adjust the technical configuration to match the required song length and select the most appropriate AI model for the genre.
Review the generated audio outputs and download the final versions in the necessary format for video integration.
While the AI is capable of incredible feats, it is not a mind reader. Achieving emotional nuance requires a thoughtful approach to prompt construction. If a track feels too "flat," it may be because the prompt lacked dynamic instructions such as "crescendo" or "intense build-up." Furthermore, harmonic complexity—such as unexpected chord changes or intricate counter-melodies—often requires a more detailed description of the musical style. I have observed that the best results come from an iterative process where the creator generates a few versions, identifies what works, and then refines the prompt for a final, more polished generation. It is a collaborative dance between human intent and machine execution.
If you enjoy PWInsider.com you can check out the AD-FREE PWInsider Elite section, which features exclusive audio updates, news, our critically acclaimed podcasts, interviews and more by clicking here!
![]()
| Jai club | Tiranga Game | Dg club | Jai Game | Yaar win | 6 Club | Bdg Play | 55 club | vn168 | 92lottery | vn168 | Jai club | Pinoy365 |










 Bang On Casino
Bang On Casino

